1. Machine Learning with Python
By Bernd Klein. Last modified: 16 Jan 2024.

What is Machine Learning?
Machine learning is a subfield of Artificial Intelligence (AI). So what is Artificial Intelligence?
Andrew Moore, former Dean of the School of Computer Science at Carnegie Mellon University, defined it as follows: "Artificial intelligence is the science and engineering of making computers behave in ways that, until recently, we thought required human intelligence."
The question "What is artificial intelligence?" depends on the answer to a more general question: "What is intelligence?"
It shows extremels hard to answer the previous question.
To get closer to the answers we can divide AI into to partitions:
weak AI and strong AI
weak AI:
- deals with specific application problems
- Supporting human thinking in certain areas
- capable of learning in sub-areas
- no awareness
strong AI:
- "general intelligence" (reason, logical thinking, use strategy, solve puzzles, and make judgments under uncertainty)
- Comparable to human intelligence, but need not be the same, could be different
- making plans
- generally capable of learning
- Communication skills, natural language
- Awareness?
- sentience, emotions?
- self-perception?
We know now about Artificial Intelligence and Weak and Strong AI, but what about Machine Learning?
Let's start with a very "old" attempt at a definition by Arthur Samuek, an IBM pioneer:
"Machine Learning: Field of study that gives computers the ability to learn without being explicitly programmed."
A good attempt, but many questions remain unanswered. Almost 40 years later, in 1998, Tom Mitchell shaped a "well-off learning problem" as follows:
"Well posed Learning Problem: A computer program is said to learn from experience E with respect to some task T and some performance measure P, if its performance on T, as measured by P, improves with experience E."
Annotation: A mathematical problem is called correctly (also well-posed, well-posed or properly posed) if the following conditions are met:
- The problem has a solution (existence).
- This solution is clearly defined (uniqueness).
- the solution's behaviour changes continuously with the initial input data (stability).
So what is Machine Learning?
Let's start with a very "old" attempt at a definition by Arthur Samuek, an IBM pioneer:
"Machine Learning: Field of study that gives computers the ability to learn without being explicitly programmed."
A commendable effort, but many questions remain unanswered. Above all one important question: What is learning? Nearly 40 years later, in 1988, another pioneer in machine learning, Tom Mitchell, formulates a "well-posed learning problem" as follows.
"Well posed Learning Problem: A computer program is said to learn from experience E with respect to some task T and some performance measure P, if its performance on T, as measured by P, improves with experience E.“
Machine learning means that an algorithm (the machine) learns automatically. This means that it is capable of extracting the necessary knowledge from given data automatically. The goal is to make predictions on new, unseen data. There is another way of putting it: In traditional heuristic decision-making algorithms, the programmers set the rules according to which the decisions are made. With machine learning, this is done independently by the program without interence from human beings!
Live Python training

Enjoying this page? We offer live Python training courses covering the content of this site.
See our Python training courses
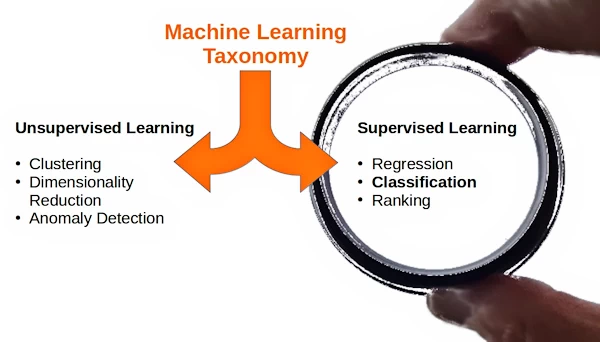
Machine learning taxonomy
There are two different approaches to Machine Learning:
- Unsupervised Learning
- Supervised Learning
Supervised Learning
In supervised learning, we have a dataset that consists of both input features and a desired outcome, as in the example of Spam/No-Spam. The task is to create a model (or program) that can predict the desired output of an unknown object based on its features.
Some more complex examples include:
- Identifying a character when given a pixel image of the character.
- Having an image of animals like "dogs," "cats," "cows," "sheep" and determining which animal it is.
- Identifying people in photos.
- Determining, based on a list of books or movies, which other books or movies a person might like.
These tasks share the characteristic that there is one or more unknown quantities associated with the object that need to be inferred from observed features.
Supervised learning is further divided into two categories:
-
Classification:

-
Regression:
-

In a nutshell: Classification involves the prediction of a label, while regression involves the prediction of a quantity.
-
In classification, the label is discrete, such as "Spam" or "Not Spam." In other words, it provides a clear distinction between categories. It's important to note that class labels represent nominal-scaled variables, not ordinal-scaled variables. Nominal and ordinal variables are both subcategories of categorical variables. Ordinal variables have a specific order, for example, T-shirt sizes "XL > L > M > S." On the other hand, nominal variables do not imply any order, for example, we cannot assume "orange > blue > green."
-
In regression, the label is continuous, meaning a floating-point output.
For example, determining which animal ("Dog," "Cat," "Cow," "Sheep") is depicted in an image is a classification problem, involving four distinct categories, i.e. the four animal kinds. On the other hand, estimating the age of an object based on some observations would be a regression problem because the label (age) is a continuous quantity.
In supervised learning, a distinction is always made between a training set (dataset) where the desired outcome is provided or known and a test set where the desired outcome needs to be inferred or calculated. The learning model adjusts the prediction model to the training set, and we use the test set to evaluate its generalization performance.
Unsupervised Learning
In "Unsupervised Learning," no desired output is assigned to the data. Instead, the goal is to extract some form of knowledge or model from the given data. In a sense, unsupervised learning can be thought of as a means to discover labels from the data itself. Unsupervised learning is often more challenging to comprehend and evaluate.
Unsupervised learning encompasses tasks such as dimensionality reduction, clustering, and density estimation. For instance, in the previously discussed Iris dataset, unsupervised methods can be used to determine combinations of measurements that best represent the data's structure.
- Determining, based on detailed observations of distant galaxies, which features or combinations of features best summarize the information.
- Separating a mixture of two sound sources (e.g., a person speaking while music is playing).
- Isolating a moving object in a given video and categorizing it in relation to other moving objects observed.
- In a large collection of news articles, finding recurring themes.
- In a specific image collection, grouping similar images into clusters (for instance, for visualization purposes).
Sometimes, the two types of learning can be combined: for example, unsupervised learning can be used to identify useful features in heterogeneous data, and these features can then be utilized in a supervised framework.
Examples for machine learning:
- spam filter: the algorithm learns a predictive model from data labelled as spam and "no spam" (ham). After training it can predict for new emails whether they are spam or not.
- character recognition
- object recognition in images
- and many more
As already mentioned, a spam filter could be implemented using a classifier based on machine learning.
At the heart of machine learning is the concept of automating decision making from data without the user specifying explicit rules on how to make that decision. In the case of emails, the user does not provide a list of words or features that spam an email. Instead, the user provides examples of spam and non-spam emails that are marked as such. This is the so-called learning set.
The goal of a machine learning model is to predict new, previously invisible data. In a real application, we are not interested in marking an already marked email as spam or not. Instead, we want to make life easier for users by automatically classifying new incoming emails.
These examples are then learned or trained by the algorithm:
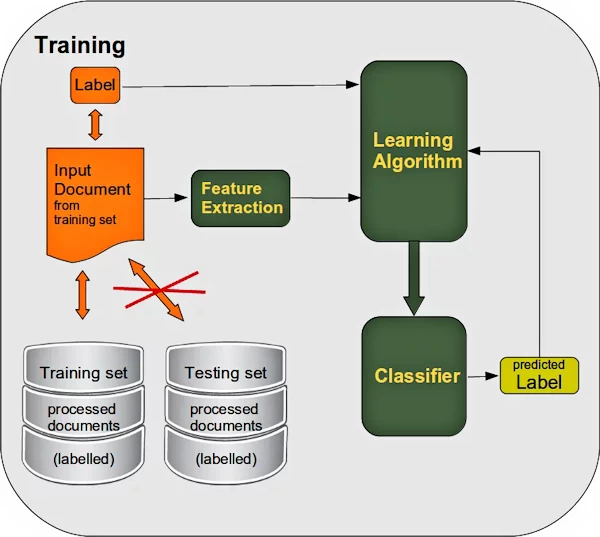
After the learning phase, we have to evaluate the classifier. We test both on labeled learning data and on non-learned labeled test data:
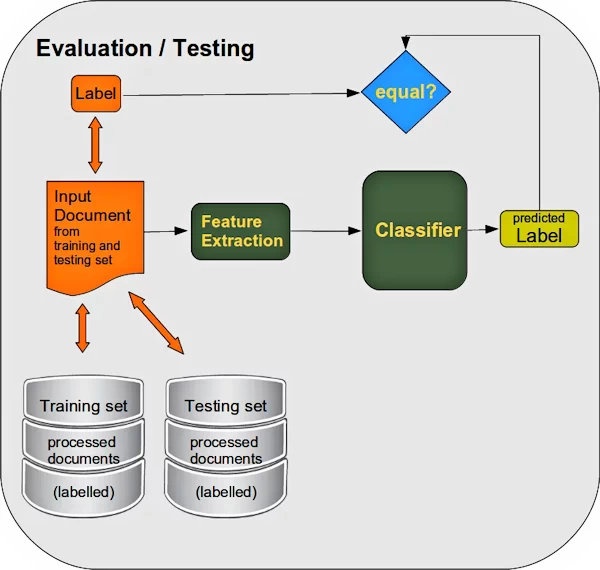
If we are satisfied with the results, the classifier is ready to classify completely new documents:
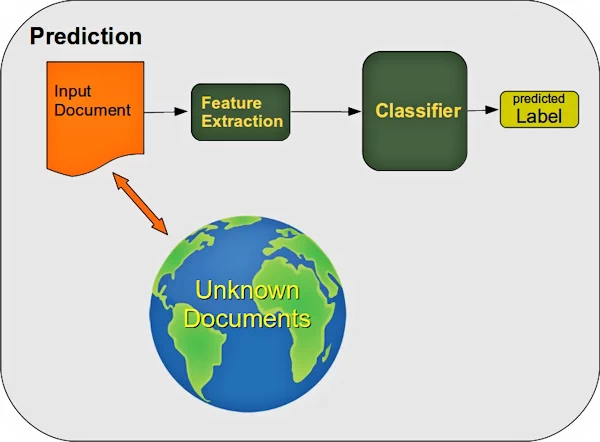
The data is presented to the algorithm usually as a two-dimensional array (or matrix) of numbers. Each data point (also known as a sample or training instance) that we want to either learn from or make a decision on is represented as a list of numbers, a so-called feature vector, and its containing features represent the properties of this point.
Live Python training
Enjoying this page? We offer live Python training courses covering the content of this site.
Upcoming online Courses
See our Python training courses