27. Text Classification in Python
By Bernd Klein. Last modified: 17 Feb 2022.
Introduction
In the previous chapter, we have deduced the formula for calculating the probability that a document d belongs to a category or class c, denoted as P(c|d).
We have transformed the standard formular for P(c|d), as it is used in many treatises1, into a numerically stable form.
We use a Naive Bayes classifier for our implementation in Python. The formal introduction into the Naive Bayes approach can be found in our previous chapter.

Python is ideal for text classification, because of it's strong string class with powerful methods. Furthermore the regular expression module re of Python provides the user with tools, which are way beyond other programming languages.
The only downside might be that this Python implementation is not tuned for efficiency.
Live Python training

Enjoying this page? We offer live Python training courses covering the content of this site.
See our Python training courses
Python Implementation of Previous Chapter
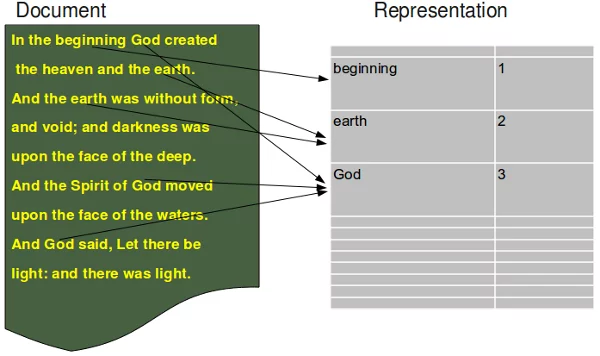
Document Representation
The document representation, which is based on the bag of word model, is illustrated in the following diagram:
Imports Needed
Our implementation needs the regular expression module re and the os module:
import re
import os
We will use in our implementation the function dict_merge_sum from the exercise 1 of our chapter on dictionaries:
def dict_merge_sum(d1, d2):
""" Two dicionaries d1 and d2 with numerical values and
possibly disjoint keys are merged and the values are added if
the exist in both values, otherwise the missing value is taken to
be 0"""
return { k: d1.get(k, 0) + d2.get(k, 0) for k in set(d1) | set(d2) }
d1 = dict(a=4, b=5, d=8)
d2 = dict(a=1, d=10, e=9)
dict_merge_sum(d1, d2)
OUTPUT:
{'e': 9, 'd': 18, 'a': 5, 'b': 5}
BagOfWordsClass
class BagOfWords(object):
""" Implementing a bag of words, words corresponding with their
frequency of usages in a "document" for usage by the
Document class, Category class and the Pool class."""
def __init__(self):
self.__number_of_words = 0
self.__bag_of_words = {}
def __add__(self, other):
""" Overloading of the "+" operator to join two BagOfWords """
erg = BagOfWords()
erg.__bag_of_words = dict_merge_sum(self.__bag_of_words,
other.__bag_of_words)
return erg
def add_word(self,word):
""" A word is added in the dictionary __bag_of_words"""
self.__number_of_words += 1
if word in self.__bag_of_words:
self.__bag_of_words[word] += 1
else:
self.__bag_of_words[word] = 1
def len(self):
""" Returning the number of different words of an object """
return len(self.__bag_of_words)
def Words(self):
""" Returning a list of the words contained in the object """
return self.__bag_of_words.keys()
def BagOfWords(self):
""" Returning the dictionary, containing the words (keys) with their frequency (values)"""
return self.__bag_of_words
def WordFreq(self,word):
""" Returning the frequency of a word """
if word in self.__bag_of_words:
return self.__bag_of_words[word]
else:
return 0
The Document class
class Document(object):
""" Used both for learning (training) documents and for testing documents. The optional parameter lear
has to be set to True, if a classificator should be trained. If it is a test document learn has to be set to False. """
_vocabulary = BagOfWords()
def __init__(self, vocabulary):
self.__name = ""
self.__document_class = None
self._words_and_freq = BagOfWords()
Document._vocabulary = vocabulary
def read_document(self,filename, learn=False):
""" A document is read. It is assumed that the document is either encoded in utf-8 or in iso-8859... (latin-1).
The words of the document are stored in a Bag of Words, i.e. self._words_and_freq = BagOfWords() """
try:
text = open(filename,"r", encoding='utf-8').read()
except UnicodeDecodeError:
text = open(filename,"r", encoding='latin-1').read()
text = text.lower()
words = re.split(r"\W",text)
self._number_of_words = 0
for word in words:
self._words_and_freq.add_word(word)
if learn:
Document._vocabulary.add_word(word)
def __add__(self,other):
""" Overloading the "+" operator. Adding two documents consists in adding the BagOfWords of the Documents """
res = Document(Document._vocabulary)
res._words_and_freq = self._words_and_freq + other._words_and_freq
return res
def vocabulary_length(self):
""" Returning the length of the vocabulary """
return len(Document._vocabulary)
def WordsAndFreq(self):
""" Returning the dictionary, containing the words (keys) with their frequency (values) as contained
in the BagOfWords attribute of the document"""
return self._words_and_freq.BagOfWords()
def Words(self):
""" Returning the words of the Document object """
d = self._words_and_freq.BagOfWords()
return d.keys()
def WordFreq(self,word):
""" Returning the number of times the word "word" appeared in the document """
bow = self._words_and_freq.BagOfWords()
if word in bow:
return bow[word]
else:
return 0
def __and__(self, other):
""" Intersection of two documents. A list of words occuring in both documents is returned """
intersection = []
words1 = self.Words()
for word in other.Words():
if word in words1:
intersection += [word]
return intersection
Category / Collections of Documents
This is the class consisting of the documents for one category /class. We use the term category instead of "class" so that it will not be confused with Python classes:
class Category(Document):
def __init__(self, vocabulary):
Document.__init__(self, vocabulary)
self._number_of_docs = 0
def Probability(self,word):
""" returns the probabilty of the word "word" given the class "self" """
voc_len = Document._vocabulary.len()
SumN = 0
for i in range(voc_len):
SumN = Category._vocabulary.WordFreq(word)
N = self._words_and_freq.WordFreq(word)
erg = 1 + N
erg /= voc_len + SumN
return erg
def __add__(self,other):
""" Overloading the "+" operator. Adding two Category objects consists in adding the
BagOfWords of the Category objects """
res = Category(self._vocabulary)
res._words_and_freq = self._words_and_freq + other._words_and_freq
return res
def SetNumberOfDocs(self, number):
self._number_of_docs = number
def NumberOfDocuments(self):
return self._number_of_docs
The Pool class
The pool is the class, where the document classes are trained and kept:
class Pool(object):
def __init__(self):
self.__document_classes = {}
self.__vocabulary = BagOfWords()
def sum_words_in_class(self, dclass):
""" The number of times all different words of a dclass appear in a class """
sum = 0
for word in self.__vocabulary.Words():
WaF = self.__document_classes[dclass].WordsAndFreq()
if word in WaF:
sum += WaF[word]
return sum
def learn(self, directory, dclass_name):
""" directory is a path, where the files of the class with the name dclass_name can be found """
x = Category(self.__vocabulary)
dir = os.listdir(directory)
for file in dir:
d = Document(self.__vocabulary)
#print(directory + "/" + file)
d.read_document(directory + "/" + file, learn = True)
x = x + d
self.__document_classes[dclass_name] = x
x.SetNumberOfDocs(len(dir))
def Probability(self, doc, dclass = ""):
"""Calculates the probability for a class dclass given a document doc"""
if dclass:
sum_dclass = self.sum_words_in_class(dclass)
prob = 0
d = Document(self.__vocabulary)
d.read_document(doc)
for j in self.__document_classes:
sum_j = self.sum_words_in_class(j)
prod = 1
for i in d.Words():
wf_dclass = 1 + self.__document_classes[dclass].WordFreq(i)
wf = 1 + self.__document_classes[j].WordFreq(i)
r = wf * sum_dclass / (wf_dclass * sum_j)
prod *= r
prob += prod * self.__document_classes[j].NumberOfDocuments() / self.__document_classes[dclass].NumberOfDocuments()
if prob != 0:
return 1 / prob
else:
return -1
else:
prob_list = []
for dclass in self.__document_classes:
prob = self.Probability(doc, dclass)
prob_list.append([dclass,prob])
prob_list.sort(key = lambda x: x[1], reverse = True)
return prob_list
def DocumentIntersectionWithClasses(self, doc_name):
res = [doc_name]
for dc in self.__document_classes:
d = Document(self.__vocabulary)
d.read_document(doc_name, learn=False)
o = self.__document_classes[dc] & d
intersection_ratio = len(o) / len(d.Words())
res += (dc, intersection_ratio)
return res
Using the Classifier
To be able to learn and test a classifier, we offer a "Learn and test set to Download". The module NaiveBayes consists of the code we have provided so far, but it can be downloaded for convenience as NaiveBayes.py The learn and test sets contain (old) jokes labelled in six categories: "clinton", "lawyer", "math", "medical", "music", "sex".
import os
DClasses = ["clinton", "lawyer", "math", "medical", "music", "sex"]
base = "data/jokes/learn/"
p = Pool()
for dclass in DClasses:
p.learn(base + dclass, dclass)
base = "data/jokes/test/"
results = []
for dclass in DClasses:
dir = os.listdir(base + dclass)
for file in dir:
res = p.Probability(base + dclass + "/" + file)
results.append(f"{dclass}: {file}: {str(res)}")
print(results[:10])
OUTPUT:
["clinton: clinton13.txt: [['clinton', 0.9999999999994136], ['lawyer', 4.836910173924097e-13], ['medical', 1.0275816932480502e-13], ['sex', 2.259655644772941e-20], ['music', 1.9461534629330693e-23], ['math', 1.555345744116502e-26]]", "clinton: clinton53.txt: [['clinton', 1.0], ['medical', 9.188673872554947e-27], ['lawyer', 1.8427106994083583e-27], ['sex', 1.5230675259429155e-27], ['music', 1.1695224390877453e-31], ['math', 1.1684669623309053e-33]]", "clinton: clinton43.txt: [['clinton', 0.9999999931196475], ['lawyer', 5.860057747465498e-09], ['medical', 9.607574904397297e-10], ['sex', 5.894524557321511e-11], ['music', 3.7727719397911977e-13], ['math', 2.147560501376133e-13]]", "clinton: clinton3.txt: [['clinton', 0.9999999999999962], ['music', 2.2781994419060397e-15], ['medical', 1.1698375401225822e-15], ['lawyer', 4.527194012614925e-16], ['sex', 1.5454131826930606e-17], ['math', 7.079852963638893e-18]]", "clinton: clinton33.txt: [['clinton', 0.9999999999990845], ['sex', 4.541025305456911e-13], ['lawyer', 3.126691883689181e-13], ['medical', 1.3677618519146697e-13], ['music', 1.2066374685712134e-14], ['math', 7.905002788169863e-19]]", "clinton: clinton23.txt: [['clinton', 0.9999999990044788], ['music', 9.903297627375497e-10], ['lawyer', 4.599127712898122e-12], ['math', 5.204515552253461e-13], ['sex', 6.840062626646056e-14], ['medical', 3.2400016635923044e-15]]", "lawyer: lawyer203.txt: [['lawyer', 0.9786187307635054], ['music', 0.009313838824293683], ['clinton', 0.007226994270357742], ['sex', 0.004650195377700058], ['medical', 0.00019018203662436446], ['math', 5.87275188878159e-08]]", "lawyer: lawyer233.txt: [['music', 0.7468245708838688], ['lawyer', 0.2505817879364303], ['clinton', 0.0025913149343268467], ['medical', 1.71345437802292e-06], ['sex', 6.081558428153343e-07], ['math', 4.635153054869146e-09]]", "lawyer: lawyer273.txt: [['clinton', 1.0], ['lawyer', 3.1987559043152286e-46], ['music', 1.3296257614591338e-54], ['math', 9.431988300101994e-85], ['sex', 3.1890112632916554e-91], ['medical', 1.5171123775659174e-99]]", "lawyer: lawyer213.txt: [['lawyer', 0.9915688655897351], ['music', 0.005065592126015617], ['clinton', 0.003206989396712446], ['math', 6.94882106646087e-05], ['medical', 6.923689581139796e-05], ['sex', 1.982778106069595e-05]]"]
Footnotes
1 Please see our "Further Reading" section of our previous chapter
Live Python training
Enjoying this page? We offer live Python training courses covering the content of this site.
Upcoming online Courses
See our Python training courses