14. Neural Networks, Structure, Weights and Matrices
By Bernd Klein. Last modified: 19 Apr 2024.
Introduction

We introduced the basic ideas about neural networks in the previous chapter of our machine learning tutorial.
We have pointed out the similarity between neurons and neural networks in biology. We also introduced very small articial neural networks and introduced decision boundaries and the XOR problem.
In the simple examples we introduced so far, we saw that the weights are the essential parts of a neural network. Before we start to write a neural network with multiple layers, we need to have a closer look at the weights.
We have to see how to initialize the weights and how to efficiently multiply the weights with the input values.
In the following chapters we will design a neural network in Python, which consists of three layers, i.e. the input layer, a hidden layer and an output layer. You can see this neural network structure in the following diagram. We have an input layer with three nodes $i_1, i_2, i_3$ These nodes get the corresponding input values $x_1, x_2, x_3$. The middle or hidden layer has four nodes $h_1, h_2, h_3, h_4$. The input of this layer stems from the input layer. We will discuss the mechanism soon. Finally, our output layer consists of the two nodes $o_1, o_2$
The input layer is different from the other layers. The nodes of the input layer are passive. This means that the input neurons do not change the data, i.e. there are no weights used in this case. They receive a single value and duplicate this value to their many outputs.
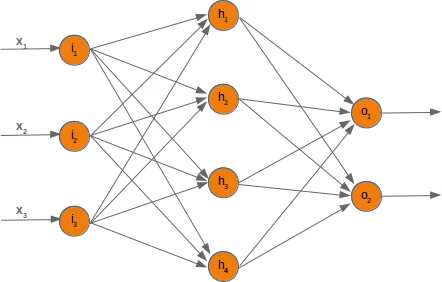
The input layer consists of the nodes $i_1$, $i_2$ and $i_3$. In principle the input is a one-dimensional vector, like (2, 4, 11). A one-dimensional vector is represented in numpy like this:
import numpy as np
input_vector = np.array([2, 4, 11])
print(input_vector)
OUTPUT:
[ 2 4 11]
In the algorithm, which we will write later, we will have to transpose it into a column vector, i.e. a two-dimensional array with just one column:
import numpy as np
input_vector = np.array([2, 4, 11])
input_vector = np.array(input_vector, ndmin=2).T
print("The input vector:\n", input_vector)
print("The shape of this vector: ", input_vector.shape)
OUTPUT:
The input vector: [[ 2] [ 4] [11]] The shape of this vector: (3, 1)
Live Python training

Enjoying this page? We offer live Python training courses covering the content of this site.
See our Python training courses
Weights and Matrices
Each of the arrows in our network diagram has an associated weight value. We will only look at the arrows between the input and the output layer now.

The value $x_1$ going into the node $i_1$ will be distributed according to the values of the weights. In the following diagram we have added some example values. Using these values, the input values ($Ih_1, Ih_2, Ih_3, Ih_4$ into the nodes ($h_1, h_2, h_3, h_4$) of the hidden layer can be calculated like this:
$Ih_1 = 0.81 * 0.5 + 0.12 * 1 + 0.92 * 0.8 $
$Ih_2 = 0.33 * 0.5 + 0.44 * 1 + 0.72 * 0.8 $
$Ih_3 = 0.29 * 0.5 + 0.22 * 1 + 0.53 * 0.8 $
$Ih_4 = 0.37 * 0.5 + 0.12 * 1 + 0.27 * 0.8 $
Those familiar with matrices and matrix multiplication will see where it is boiling down to. We will redraw our network and denote the weights with $w_{ij}$, i.e. the node from the input node $i_i$ to the hidden node $h_i$:

In order to efficiently execute all the necessary calaculations, we will arrange the weights into a weight matrix. The weights in our diagram above build an array, which we will call 'weights_in_hidden' in our Neural Network class. The name should indicate that the weights are connecting the input and the hidden nodes, i.e. they are between the input and the hidden layer. We will also abbreviate the name as 'wih'. The weight matrix between the hidden and the output layer will be denoted as "who".:
Now that we have defined our weight matrices, we have to take the next step. We have to multiply the matrix wih the input vector. Btw. this is exactly what we have manually done in our previous example.
We have a similar situation for the 'who' matrix between hidden and output layer. So the output $z_1$ and $z_2$ from the nodes $o_1$ and $o_2$ can also be calculated with matrix multiplications:
The following picture depicts the whole flow of calculation, i.e. the matrix multiplication and the succeeding application of the activation function.
The matrix multiplication between the matrix wih and the matrix of the values of the input nodes $x_1, x_2, x_3$ calculates the output which will be passed to the activation function.

The final output $y_1, y_2, y_3, y_4$ is the input of the weight matrix who:
Even though treatment is completely analogue, we will also have a detailled look at what is going on between our hidden layer and the output layer:
 )
)
Initializing the weight matrices
One of the important choices which have to be made before training a neural network consists in initializing the weight matrices. We don't know anything about the possible weights, when we start. So, we could start with arbitrary values?
As we have seen the input to all the nodes except the input nodes is calculated by applying the activation function to the following sum:
(with n being the number of nodes in the previous layer and $y_j$ is the input to a node of the next layer)
We can easily see that it would not be a good idea to set all the weight values to 0, because in this case the result of this summation will always be zero. This means that our network will be incapable of learning. This is the worst choice, but initializing a weight matrix to ones is also a bad choice.
The values for the weight matrices should be chosen randomly and not arbitrarily. By choosing a random normal distribution we have broken possible symmetric situations, which can and often are bad for the learning process.
There are various ways to initialize the weight matrices randomly. The first one we will introduce is the unity function from numpy.random. It creates samples which are uniformly distributed over the half-open interval [low, high), which means that low is included and high is excluded. Each value within the given interval is equally likely to be drawn by 'uniform'.
import numpy as np
number_of_samples = 1200
low = -1
high = 0
s = np.random.uniform(low, high, number_of_samples)
# all values of s are within the half open interval [-1, 0) :
print(np.all(s >= -1) and np.all(s < 0))
OUTPUT:
True
The histogram of the samples, created with the uniform function in our previous example, looks like this:
import matplotlib.pyplot as plt
plt.hist(s)
plt.show()

The next function we will look at is 'binomial' from numpy.binomial:
binomial(n, p, size=None)
It draws samples from a binomial distribution with specified parameters,
n trials and probability p of success where n is an integer >= 0 and p is
a float in the interval [0,1]. (n may be input as a float, but it is truncated to an integer in use)
s = np.random.binomial(100, 0.5, 1200)
plt.hist(s)
plt.show()

We like to create random numbers with a normal distribution, but the numbers have to be bounded. This is not the case with np.random.normal(), because it doesn't offer any bound parameter.
We can use truncnorm from scipy.stats for this purpose.
The standard form of this distribution is a standard normal truncated to the range [a, b] — notice that a and b are defined over the domain of the standard normal. To convert clip values for a specific mean and standard deviation, use:
a, b = (myclip_a - my_mean) / my_std, (myclip_b - my_mean) / my_std
from scipy.stats import truncnorm
s = truncnorm(a=-2/3., b=2/3., scale=1, loc=0).rvs(size=1000)
plt.hist(s)
plt.show()

The function 'truncnorm' is difficult to use. To make life easier, we define a function truncated_normal in the following to fascilitate this task:
def truncated_normal(mean=0, sd=1, low=0, upp=10):
return truncnorm(
(low - mean) / sd, (upp - mean) / sd, loc=mean, scale=sd)
X = truncated_normal(mean=0, sd=0.4, low=-0.5, upp=0.5)
s = X.rvs(10000)
plt.hist(s)
plt.show()

Further examples:
X1 = truncated_normal(mean=2, sd=1, low=1, upp=10)
X2 = truncated_normal(mean=5.5, sd=1, low=1, upp=10)
X3 = truncated_normal(mean=8, sd=1, low=1, upp=10)
import matplotlib.pyplot as plt
fig, ax = plt.subplots(3, sharex=True)
ax[0].hist(X1.rvs(10000), density=True)
ax[1].hist(X2.rvs(10000), density=True)
ax[2].hist(X3.rvs(10000), density=True)
plt.show()

We will create the link weights matrix now. truncated_normal is ideal for this purpose.
It is a good idea to choose random values from within the interval
where n denotes the number of input nodes.
So we can create our "wih" matrix with:
no_of_input_nodes = 3
no_of_hidden_nodes = 4
rad = 1 / np.sqrt(no_of_input_nodes)
X = truncated_normal(mean=2, sd=1, low=-rad, upp=rad)
wih = X.rvs((no_of_hidden_nodes, no_of_input_nodes))
wih
OUTPUT:
array([[ 0.26321879, 0.10101008, -0.37148814],
[ 0.17460107, 0.02250573, 0.2628983 ],
[-0.38430878, -0.03294092, -0.44984485],
[-0.22071797, 0.5543815 , -0.24451279]])
Similarly, we can now define the "who" weight matrix:
no_of_hidden_nodes = 4
no_of_output_nodes = 2
rad = 1 / np.sqrt(no_of_hidden_nodes) # this is the input in this layer!
X = truncated_normal(mean=2, sd=1, low=-rad, upp=rad)
who = X.rvs((no_of_output_nodes, no_of_hidden_nodes))
who
OUTPUT:
array([[ 0.42490161, 0.30510373, 0.13183435, -0.03681322],
[ 0.36781937, 0.28030039, 0.28682673, 0.39464687]])
Live Python training
Enjoying this page? We offer live Python training courses covering the content of this site.
Upcoming online Courses
See our Python training courses