15. Regular Expressions
By Bernd Klein. Last modified: 08 Mar 2024.
The aim of this chapter of our Python tutorial is to present a detailed and descriptive introduction into regular expressions. This introduction will explain the theoretical aspects of regular expressions and will show you how to use them in Python scripts.
The term "regular expression", sometimes also called regex or regexp, has originated in theoretical computer science. In theoretical computer science, they are used to define a language family with certain characteristics, the so-called regular languages. A finite state machine (FSM), which accepts language defined by a regular expression, exists for every regular expression. You can find an implementation of a Finite State Machine in Python on our website.
Regular Expressions are used in programming languages to filter texts or textstrings. It's possible to check, if a text or a string matches a regular expression. A great thing about regular expressions: The syntax of regular expressions is the same for all programming and script languages, e.g. Python, Perl, Java, SED, AWK and even X#.
The first programs which had incorporated the capability to use regular expressions were the Unix tools ed (editor), the stream editor sed and the filter grep.
There is another mechanism in operating systems, which shouldn't be mistaken for regular expressions. Wildcards, also known as globbing, look very similar in their syntax to regular expressions. However, the semantics differ considerably. Globbing is known from many command line shells, like the Bourne shell, the Bash shell or even DOS. In Bash e.g. the command "ls .txt" lists all files (or even directories) ending with the suffix .txt; in regular expression notation ".txt" wouldn't make sense, it would have to be written as ".*.txt"
Introduction

When we introduced the sequential data types, we got to know the "in" operator. We check in the following example, if the string "easily" is a substring of the string "Regular expressions easily explained!":
s = "Regular expressions easily explained!"
"easily" in s
OUTPUT:
True
We show step by step with the following diagrams how this matching is performed: We check if the string sub = "abc"
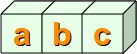
is contained in the string s = "xaababcbcd"

By the way, the string sub = "abc" can be seen as a regular expression, just a very simple one.
In the first place, we check, if the first positions of the two string match, i.e. s[0] == sub[0]. This is not satisfied in our example. We mark this fact by the colour red:
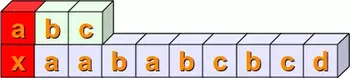
Then we check, if s[1:4] == sub. In other words, we have to check at first, if sub[0] is equal to s[1]. This is true and we mark it with the colour green. Then, we have to compare the next positions. s[2] is not equal to sub[1], so we don't have to proceed further with the next position of sub and s:
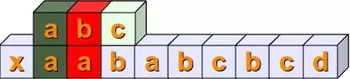
Now we have to check if s[2:5] and sub are equal. The first two positions are equal but not the third:
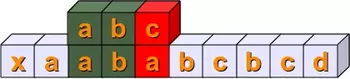
The following steps should be clear without any explanations:
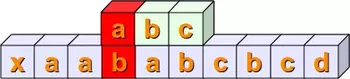
Finally, we have a complete match with s[4:7] == sub :
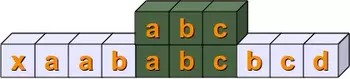
Live Python training

Enjoying this page? We offer live Python training courses covering the content of this site.
See our Python training courses
A Simple Regular Expression
As we have already mentioned in the previous section, we can see the variable "sub" from the introduction as a very simple regular expression. If you want to use regular expressions in Python, you have to import the re module, which provides methods and functions to deal with regular expressions.
Representing Regular Expressions in Python
From other languages you might be used to representing regular expressions within Slashes "/", e.g. that's the way Perl, SED or AWK deals with them. In Python there is no special notation. Regular expressions are represented as normal strings.
But this convenience brings along a small problem: The backslash is a special character used in regular expressions, but is also used as an escape character in strings. This implies that Python would first evaluate every backslash of a string and after this - without the necessary backslashes - it would be used as a regular expression. One way to prevent this could be writing every backslash as "\" and this way keep it for the evaluation of the regular expression. This can cause extremely clumsy expressions. E.g. a backslash in a regular expression has to be written as a double backslash, because the backslash functions as an escape character in regular expressions. Therefore, it has to be quoted. The same is valid for Python strings. The backslash has to be quoted by a backslash. So, a regular expression to match the Windows path "C:\programs" corresponds to a string in regular expression notation with four backslashes, i.e. "C:\\programs".
The best way to overcome this problem would be marking regular expressions as raw strings. The solution to our Windows path example looks like this as a raw string:
r"C:\\programs"
Let's look at another example, which might be quite disturbing for people who are used to wildcards:
r"^a.*\.html$"
The regular expression of our previous example matches all file names (strings) which start with an "a" and end with ".html". We will the structure of the example above in detail explain in the following sections.
Live Python training
Enjoying this page? We offer live Python training courses covering the content of this site.
Upcoming online Courses
28 Jul to 01 Aug 2025
08 Sep to 12 Sep 2025
20 Oct to 24 Oct 2025
01 Dec to 05 Dec 2025
Efficient Data Analysis with Pandas
28 Jul to 29 Jul 2025
08 Sep to 09 Sep 2025
20 Oct to 21 Oct 2025
01 Dec to 02 Dec 2025
Python and Machine Learning Course
28 Jul to 01 Aug 2025
08 Sep to 12 Sep 2025
20 Oct to 24 Oct 2025
01 Dec to 05 Dec 2025
See our Python training courses
Syntax of Regular Expression
r"cat"
is a regular expression, though a very simple one without any metacharacters. Our RE
r"cat"
matches, for example, the following string: "A cat and a rat can't be friends."
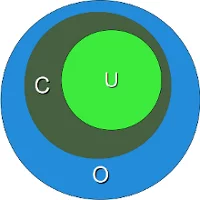
Interestingly, the previous example shows already a "favourite" example for a mistake, frequently made not only by beginners and novices but also by advanced users of regular expressions. The idea of this example is to match strings containing the word "cat". We are successful at this, but unfortunately we are matching a lot of other words as well. If we match "cats" in a string that might be still okay, but what about all those words containing this character sequence "cat"? We match words like "education", "communicate", "falsification", "ramifications", "cattle" and many more. This is a case of "over matching", i.e. we receive positive results, which are wrong according to the problem we want to solve.
We have illustrated this problem in the diagram above. The dark green Circle C corresponds to the set of "objects" we want to recognize. But instead we match all the elements of the set O (blue circle). C is a subset of O. The set U (light green circle) in this diagram is a subset of C. U is a case of "under matching", i.e. if the regular expression is not matching all the intended strings. If we try to fix the previous RE, so that it doesn't create over matching, we might try the expression
r" cat "
. These blanks prevent the matching of the above mentioned words like "education", "falsification" and "ramification", but we fall prey to another mistake. What about the string "The cat, called Oscar, climbed on the roof."? The problem is that we don't expect a comma but only a blank surrounding the word "cat".
Before we go on with the description of the syntax of regular expressions, we want to explain how to use them in Python:
import re
x = re.search("cat", "A cat and a rat can't be friends.")
print(x)
OUTPUT:
<re.Match object; span=(2, 5), match='cat'>
x = re.search("cow", "A cat and a rat can't be friends.")
print(x)
OUTPUT:
None
In the previous example we had to import the module re to be able to work with regular expressions. Then we used the method search from the re module. This is most probably the most important and the most often used method of this module. re.search(expr,s) checks a string s for an occurrence of a substring which matches the regular expression expr. The first substring (from left), which satisfies this condition will be returned. If a match has been possible, we get a so-called match object as a result, otherwise the value will be None. This method is already enough to use regular expressions in a basic way in Python programs. We can use it in conditional statements: If a regular expression matches, we get an SRE object returned, which is taken as a True value, and None, which is the return value if it doesn't match, is taken as False:
if re.search("cat", "A cat and a rat can't be friends."):
print("Some kind of cat has been found :-)")
else:
print("No cat has been found :-)")
OUTPUT:
Some kind of cat has been found :-)
if re.search("cow", "A cat and a rat can't be friends."):
print("Cats and Rats and a cow.")
else:
print("No cow around.")
OUTPUT:
No cow around.
Any Character
Let's assume that we have not been interested in the previous example to recognize the word cat, but all three letter words, which end with "at". The syntax of regular expressions supplies a metacharacter ".", which is used like a placeholder for "any character". The regular expression of our example can be written like this: r" .at " This RE matches three letter words, isolated by blanks, which end in "at". Now we get words like "rat", "cat", "bat", "eat", "sat" and many others.
But what if the text contains "words" like "@at" or "3at"? These words match as well, meaning we have caused over matching again. We will learn a solution in the following section.
Character Classes
Square brackets, "[" and "]", are used to include a character class. [xyz] means e.g. either an "x", an "y" or a "z". Let's look at a more practical example:
r"M[ae][iy]er"
This is a regular expression, which matches a surname which is quite common in German. A name with the same pronunciation and four different spellings: Maier, Mayer, Meier, Meyer A finite state automata to recognize this expression can be build like this:
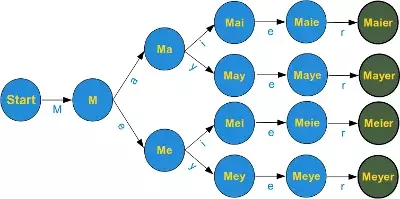
The graph of the finite state machine (FSM) is simplified to keep the design easy. There should be an arrow in the start node pointing back on its own, i.e. if a character other than an upper case "M" has been processed, the machine should stay in the start condition. Furthermore, there should be an arrow pointing back from all nodes except the final nodes (the green ones) to the start node, unless the expected letter has been processed. E.g. if the machine is in state Ma, after having processed a "M" and an "a", the machine has to go back to state "Start", if any character except "i" or "y" can be read. Those who have problems with this FSM, shouldn't worry, since it is not a prerequisite for the rest of the chapter.
Instead of a choice between two characters, we often need a choice between larger character classes. We might need e.g. a class of letters between "a" and "e" or between "0" and "5". To manage such character classes, the syntax of regular expressions supplies a metacharacter "-". [a-e] a simplified writing for [abcde] or [0-5] denotes [012345].
The advantage is obvious and even more impressive, if we have to coin expressions like "any uppercase letter" into regular expressions. So instead of [ABCDEFGHIJKLMNOPQRSTUVWXYZ] we can write [A-Z]. If this is not convincing: Write an expression for the character class "any lower case or uppercase letter" [A-Za-z]
There is something more about the dash, we used to mark the begin and the end of a character class. The dash has only a special meaning if it is used within square brackets and in this case only if it isn't positioned directly after an opening or immediately in front of a closing bracket. So the expression [-az] is only the choice between the three characters "-", "a" and "z", but no other characters. The same is true for [az-].
Exercise: What character class is described by [-a-z]?
Answer The character "-" and all the characters "a", "b", "c" all the way up to "z".
The only other special character inside square brackets (character class choice) is the caret "^". If it is used directly after an opening sqare bracket, it negates the choice. [^0-9] denotes the choice "any character but a digit". The position of the caret within the square brackets is crucial. If it is not positioned as the first character following the opening square bracket, it has no special meaning. [^abc] means anything but an "a", "b" or "c" [a^bc] means an "a", "b", "c" or a "^"
A Practical Exercise in Python
Before we go on with our introduction into regular expressions, we want to insert a practical exercise with Python. We have a phone list of the Simpsons, yes, the famous Simpsons from the American animated TV series. There are some people with the surname Neu. We are looking for a Neu, but we don't know the first name, we just know that it starts with a J. Let's write a Python script, which finds all the lines of the phone book, which contain a person with the described surname and a first name starting with J. If you don't know how to read and work with files, you should work through our chapter File Management. So here is our example script:
import re
fh = open("simpsons_phone_book.txt")
for line in fh:
if re.search(r"J.*Neu",line):
print(line.rstrip())
fh.close()
OUTPUT:
Jack Neu 555-7666 Jeb Neu 555-5543 Jennifer Neu 555-3652
Instead of downloading simpsons_phone_book.txt, we can also use the file directly from the website by using urlopen from the module urllib.request:
import re
from urllib.request import urlopen
with urlopen('https://www.python-course.eu/simpsons_phone_book.txt') as fh:
for line in fh:
# line is a byte string so we transform it to utf-8:
line = line.decode('utf-8').rstrip()
if re.search(r"J.*Neu",line):
print(line)
OUTPUT:
Jack Neu 555-7666 Jeb Neu 555-5543 Jennifer Neu 555-3652
Predefined Character Classes
You might have realized that it can be quite cumbersome to construe certain character classes. A good example is the character class, which describes a valid word character. These are all lower case and uppercase characters plus all the digits and the underscore, corresponding to the following regular expression: r"[a-zA-Z0-9_]"
The special sequences consist of "\\" and a character from the following list: \d Matches any decimal digit; equivalent to the set [0-9]. \D The complement of \d. It matches any non-digit character; equivalent to the set [^0-9]. \s Matches any whitespace character; equivalent to [ \t\n\r\f\v]. \S The complement of \s. It matches any non-whitespace character; equiv. to [^ \t\n\r\f\v]. \w Matches any alphanumeric character; equivalent to [a-zA-Z0-9_]. With LOCALE, it will match the set [a-zA-Z0-9_] plus characters defined as letters for the current locale. \W Matches the complement of \w. \b Matches the empty string, but only at the start or end of a word. \B Matches the empty string, but not at the start or end of a word. \\ Matches a literal backslash.
Word boundaries
The \b and \B of the previous overview of special sequences, is often not properly understood or even misunderstood especially by novices. While the other sequences match characters, - e.g. \w matches characters like "a", "b", "m", "3" and so on, - \b and \B don't match a character. They match empty strings depending on their neighbourhood, i.e. what kind of a character the predecessor and the successor is. So \b matches any empty string between a \W and a \w character and also between a \w and a \W character. \B is the complement, i.e empty strings between \W and \W or empty strings between \w and \w. We illustrate this in the following example:
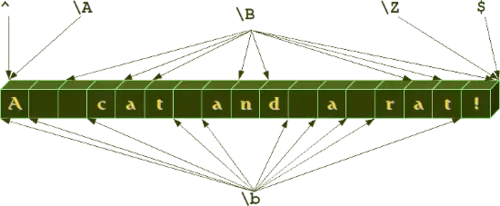
We will get to know further "virtual" matching characters, i.e. the caret (^), which is used to mark the beginning of a string, and the dollar sign ($), which is used to mark the end of a string, respectively. \A and \Z, which can also be found in our previous diagram, are very seldom used as alternatives to the caret and the dollar sign.
Matching Beginning and End
As we have previously carried out in this introduction, the expression r"M[ae][iy]er" is capable of matching various spellings of the name Mayer and the name can be anywhere in the string:
import re
line = "He is a German called Mayer."
if re.search(r"M[ae][iy]er", line):
print("I found one!")
OUTPUT:
I found one!
But what if we want to match a regular expression at the beginning of a string and only at the beginning?
The re module of Python provides two functions to match regular expressions. We have met already one of them, i.e. search(). The other has in our opinion a misleading name: match() Misleading, because match(re_str, s) checks for a match of re_str merely at the beginning of the string. But anyway, match() is the solution to our question, as we can see in the following example:
import re
s1 = "Mayer is a very common Name"
s2 = "He is called Meyer but he isn't German."
print(re.search(r"M[ae][iy]er", s1))
print(re.search(r"M[ae][iy]er", s2))
# matches because it starts with Mayer
print(re.match(r"M[ae][iy]er", s1))
# doesn't match because it doesn't start with Meyer or Meyer, Meier and so on:
print(re.match(r"M[ae][iy]er", s2))
OUTPUT:
<re.Match object; span=(0, 5), match='Mayer'> <re.Match object; span=(13, 18), match='Meyer'> <re.Match object; span=(0, 5), match='Mayer'> None
So, this is a way to match the start of a string, but it's a Python specific method, i.e. it can't be used in other languages like Perl, AWK and so on. There is a general solution which is a standard for regular expressions:
The caret '^' matches the start of the string, and in MULTILINE (will be explained further down) mode also matches immediately after each newline, which the Python method match() doesn't do. The caret has to be the first character of a regular expression:
import re
s1 = "Mayer is a very common Name"
s2 = "He is called Meyer but he isn't German."
print(re.search(r"^M[ae][iy]er", s1))
print(re.search(r"^M[ae][iy]er", s2))
OUTPUT:
<re.Match object; span=(0, 5), match='Mayer'> None
But what happens if we concatenate the two strings s1 and s2 in the following way?
s = s2 + "\n" + s1
Now the string doesn't start with a Maier of any kind, but the name follows a newline character:
s = s2 + "\n" + s1
print(re.search(r"^M[ae][iy]er", s))
OUTPUT:
None
The name hasn't been found, because only the beginning of the string is checked. It changes, if we use the multiline mode, which can be activated by adding the following parameters to search:
print(re.search(r"^M[ae][iy]er", s, re.MULTILINE))
print(re.search(r"^M[ae][iy]er", s, re.M))
print(re.match(r"^M[ae][iy]er", s, re.M))
OUTPUT:
<re.Match object; span=(40, 45), match='Mayer'> <re.Match object; span=(40, 45), match='Mayer'> None
The previous example also shows that the multiline mode doesn't affect the match method. match() never checks anything but the beginning of the string for a match.
We have learnt how to match the beginning of a string. What about the end? Of course that's possible to. The dollar sign ""isusedasametacharacterforthispurpose.′' matches the end of a string or just before the newline at the end of the string. If in MULTILINE mode, it also matches before a newline. We demonstrate the usage of the "$" character in the following example:
print(re.search(r"Python\.$","I like Python."))
print(re.search(r"Python\.$","I like Python and Perl."))
print(re.search(r"Python\.$","I like Python.\nSome prefer Java or Perl."))
print(re.search(r"Python\.$","I like Python.\nSome prefer Java or Perl.", re.M))
OUTPUT:
<re.Match object; span=(7, 14), match='Python.'> None None <re.Match object; span=(7, 14), match='Python.'>
Optional Items
If you thought that our collection of Mayer names was complete, you were wrong. There are other ones all over the world, e.g. London and Paris, who dropped their "e". So we have four more names ["Mayr", "Meyr", "Meir", "Mair"] plus our old set ["Mayer", "Meyer", "Meier", "Maier"].
If we try to figure out a fitting regular expression, we realize that we miss something. A way to tell the computer "this "e" may or may not occur". A question mark is used as a notation for this. A question mark declares that the preceding character or expression is optional.
The final Mayer-Recognizer looks now like this:
r"M[ae][iy]e?r"
A subexpression is grouped by round brackets and a question mark following such a group means that this group may or may not exist. With the following expression we can match dates like "Feb 2011" or February 2011":
r"Feb(ruary)? 2011"
Quantifiers
If you just use what we have introduced so far, you will still need a lot of things, above all some way of repeating characters or regular expressions. For this purpose, quantifiers are used. We have encountered one in the previous paragraph, i.e. the question mark.
A quantifier after a token, which can be a single character or group in brackets, specifies how often that preceding element is allowed to occur. The most common quantifiers are
- the question mark ?
- the asterisk or star character *, which is derived from the Kleene star
- and the plus sign +, derived from the Kleene cross
We have already previously used one of these quantifiers without explaining it, i.e. the asterisk. A star following a character or a subexpression group means that this expression or character may be repeated arbitrarily, even zero times.
r"[0-9]*"
The above expression matches any sequence of digits, even the empty string. r".*" matches any sequence of characters and the empty string.
Exercise: Write a regular expression which matches strings which starts with a sequence of digits - at least one digit - followed by a blank.
Solution:
r"^[0-9][0-9]* "
So, you used the plus character "+". That's fine, but in this case you have either cheated by going ahead in the text or you know already more about regular expressions than we have covered in our course :-)
Now that we mentioned it: The plus operator is very convenient to solve the previous exercise. The plus operator is very similar to the star operator, except that the character or subexpression followed by a "+" sign has to be repeated at least one time. Here follows the solution to our exercise with the plus quantifier:
Solution with the plus quantifier:
r"^[0-9]+ "
If you work with this arsenal of operators for a while, you will inevitably miss the possibility to repeat expressions for an exact number of times at some point. Let's assume you want to recognize the last lines of addresses on envelopes in Switzerland. These lines usually contain a four digits long post code followed by a blank and a city name. Using + or * are too unspecific for our purpose and the following expression seems to be too clumsy:
r"^[0-9][0-9][0-9][0-9] [A-Za-z]+"
Fortunately, there is an alternative available:
r"^[0-9]{4} [A-Za-z]*"
Now we want to improve our regular expression. Let's assume that there is no city name in Switzerland, which consists of less than 3 letters, at least 3 letters. We can denote this by [A-Za-z]{3,}. Now we have to recognize lines with German post code (5 digits) lines as well, i.e. the post code can now consist of either four or five digits:
r"^[0-9]{4,5} [A-Z][a-z]{2,}"
The general syntax is {from, to}, meaning the expression has to appear at least "from" times and not more than "to" times. {, to} is an abbreviated spelling for {0,to} and {from,} is an abbreviation for "at least from times but no upper limit"
Grouping
We can group a part of a regular expression by surrounding it with parenthesis (round brackets). This way we can apply operators to the complete group instead of a single character.
Capturing Groups and Back References
Parenthesis (round brackets, braces) are not only group subexpressions but they also create back references. The part of the string matched by the grouped part of the regular expression, i.e. the subexpression in parenthesis, is stored in a back reference. With the aid of back references we can reuse parts of regular expressions. These stored values can be both reused inside the expression itself and afterwards, when the regexpr is executed. Before we continue with our treatise about back references, we want to strew in a paragraph about match objects, which is important for our next examples with back references.
A Closer Look at the Match Objects
So far we have just checked, if an expression matched or not. We used the fact the re.search() returns a match object if it matches and None otherwise. We haven't been interested e.g. in what has been matched. The match object contains a lot of data about what has been matched, positions and so on.
A match object contains the methods group(), span(), start() and end(), as it can be seen in the following application:
import re
mo = re.search("[0-9]+", "Customer number: 232454, Date: February 12, 2011")
mo.group()
OUTPUT:
'232454'
mo.span()
OUTPUT:
(17, 23)
mo.start()
OUTPUT:
17
mo.end()
OUTPUT:
23
mo.span()[0]
OUTPUT:
17
mo.span()[1]
OUTPUT:
23
These methods are not difficult to understand. span() returns a tuple with the start and end position, i.e. the string index where the regular expression started matching in the string and ended matching. The methods start() and end() are in a way superfluous as the information is contained in span(), i.e. span()[0] is equal to start() and span()[1] is equal to end(). group(), if called without argument, it returns the substring, which had been matched by the complete regular expression. With the help of group() we are also capable of accessing the matched substring by grouping parentheses, to get the matched substring of the n-th group, we call group() with the argument n: group(n). We can also call group with more than integer argument, e.g. group(n,m). group(n,m) - provided there exists a subgoup n and m - returns a tuple with the matched substrings. group(n,m) is equal to (group(n), group(m)):
import re
mo = re.search("([0-9]+).*: (.*)", "Customer number: 232454, Date: February 12, 2011")
mo.group()
OUTPUT:
'232454, Date: February 12, 2011'
mo.group(1)
OUTPUT:
'232454'
mo.group(2)
OUTPUT:
'February 12, 2011'
mo.group(1,2)
OUTPUT:
('232454', 'February 12, 2011')
A very intuitive example are XML or HTML tags. E.g. let's assume we have a file (called "tags.txt") with content like this:
<composer> Wolfgang Amadeus Mozart </composer>
<author> Samuel Beckett </author>
<city> London </city>
We want to rewrite this text automatically to
composer: Wolfgang Amadeus Mozart author: Samuel Beckett city: London
The following little Python script does the trick. The core of this script is the regular expression. This regular expression works like this: It tries to match a less than symbol "<". After this it is reading lower case letters until it reaches the greater than symbol. Everything encountered within "<" and ">" has been stored in a back reference which can be accessed within the expression by writing \1. Let's assume \1 contains the value "composer". When the expression has reached the first ">", it continues matching, as the original expression had been "(.*)":
import re
fh = open("tags.txt")
for i in fh:
res = re.search(r"<([a-z]+)>(.*)</\1>",i)
print(res.group(1) + ": " + res.group(2))
OUTPUT:
composer: Wolfgang Amadeus Mozart author: Samuel Beckett city: London
If there are more than one pair of parenthesis (round brackets) inside the expression, the backreferences are numbered \1, \2, \3, in the order of the pairs of parenthesis.
Exercise: The next Python example makes use of three back references. We have an imaginary phone list of the Simpsons in a list. Not all entries contain a phone number, but if a phone number exists it is the first part of an entry. Then, separated by a blank, a surname follows, which is followed by first names. Surname and first name are separated by a comma. The task is to rewrite this example in the following way:
Allison Neu 555-8396 C. Montgomery Burns Lionel Putz 555-5299 Homer Jay Simpson 555-73347
Python script solving the rearrangement problem:
import re
l = ["555-8396 Neu, Allison",
"Burns, C. Montgomery",
"555-5299 Putz, Lionel",
"555-7334 Simpson, Homer Jay"]
for i in l:
res = re.search(r"([0-9-]*)\s*([A-Za-z]+),\s+(.*)", i)
print(res.group(3) + " " + res.group(2) + " " + res.group(1))
OUTPUT:
Allison Neu 555-8396 C. Montgomery Burns Lionel Putz 555-5299 Homer Jay Simpson 555-7334
Named Backreferences
In the previous paragraph we introduced "Capturing Groups" and "Back references". More precisely, we could have called them "Numbered Capturing Groups" and "Numbered Backreferences". Using capturing groups instead of "numbered" capturing groups allows you to assign descriptive names instead of automatic numbers to the groups. In the following example, we demonstrate this approach by catching the hours, minutes and seconds from a UNIX date string.
import re
s = "Sun Oct 14 13:47:03 CEST 2012"
expr = r"\b(?P<hours>\d\d):(?P<minutes>\d\d):(?P<seconds>\d\d)\b"
x = re.search(expr,s)
x.group('hours')
OUTPUT:
'13'
x.group('minutes')
OUTPUT:
'47'
x.start('minutes')
OUTPUT:
14
x.end('minutes')
OUTPUT:
16
x.span('seconds')
OUTPUT:
(17, 19)
Live Python training
Enjoying this page? We offer live Python training courses covering the content of this site.
See our Python training courses
Comprehensive Python Exercise
In this comprehensive exercise, we have to bring the information of two files together. In the first file, we have a list of nearly 15000 lines of post codes with the corresponding city names plus additional information. Here are some arbitrary lines of this file:
osm_id ort plz bundesland 1104550 Aach 78267 Baden-Württemberg ... 446465 Freiburg (Elbe) 21729 Niedersachsen 62768 Freiburg im Breisgau 79098 Baden-Württemberg 62768 Freiburg im Breisgau 79100 Baden-Württemberg 62768 Freiburg im Breisgau 79102 Baden-Württemberg ... 454863 Fulda 36037 Hessen 454863 Fulda 36039 Hessen 454863 Fulda 36041 Hessen ... 1451600 Gallin 19258 Mecklenburg-Vorpommern 449887 Gallin-Kuppentin 19386 Mecklenburg-Vorpommern ... 57082 Gärtringen 71116 Baden-Württemberg 1334113 Gartz (Oder) 16307 Brandenburg ... 2791802 Giengen an der Brenz 89522 Baden-Württemberg 2791802 Giengen an der Brenz 89537 Baden-Württemberg ... 1187159 Saarbrücken 66133 Saarland 1256034 Saarburg 54439 Rheinland-Pfalz 1184570 Saarlouis 66740 Saarland 1184566 Saarwellingen 66793 Saarland
The other file contains a list of the 19 largest German cities. Each line consists of the rank, the name of the city, the population, and the state (Bundesland):
1. Berlin 3.382.169 Berlin 2. Hamburg 1.715.392 Hamburg 3. München 1.210.223 Bayern 4. Köln 962.884 Nordrhein-Westfalen 5. Frankfurt am Main 646.550 Hessen 6. Essen 595.243 Nordrhein-Westfalen 7. Dortmund 588.994 Nordrhein-Westfalen 8. Stuttgart 583.874 Baden-Württemberg 9. Düsseldorf 569.364 Nordrhein-Westfalen 10. Bremen 539.403 Bremen 11. Hannover 515.001 Niedersachsen 12. Duisburg 514.915 Nordrhein-Westfalen 13. Leipzig 493.208 Sachsen 14. Nürnberg 488.400 Bayern 15. Dresden 477.807 Sachsen 16. Bochum 391.147 Nordrhein-Westfalen 17. Wuppertal 366.434 Nordrhein-Westfalen 18. Bielefeld 321.758 Nordrhein-Westfalen 19. Mannheim 306.729 Baden-Württemberg
Our task is to create a list with the top 19 cities, with the city names accompanied by the postal code. If you want to test the following program, you have to save the list above in a file called largest_cities_germany.txt and you have to download and save the list of German post codes.
import re
with open("zuordnung_plz_ort.txt", encoding="utf-8") as fh_post_codes:
codes4city = {}
for line in fh_post_codes:
res = re.search(r"[\d ]+([^\d]+[a-z])\s(\d+)", line)
if res:
city, post_code = res.groups()
if city in codes4city:
codes4city[city].add(post_code)
else:
codes4city[city] = {post_code}
with open("largest_cities_germany.txt", encoding="utf-8") as fh_largest_cities:
for line in fh_largest_cities:
re_obj = re.search(r"^[0-9]{1,2}\.\s+([\w\s-]+\w)\s+[0-9]", line)
city = re_obj.group(1)
print(city, codes4city[city])
OUTPUT:
Berlin {'12685', '12279', '12353', '12681', '13465', '12163', '10365', '12351', '13156', '12629', '12689', '12053', '13086', '12057', '12157', '10823', '12621', '14129', '13359', '13435', '10963', '12209', '12683', '10369', '10787', '12277', '14059', '12459', '13593', '12687', '10785', '12526', '10717', '12487', '12203', '13583', '12347', '12627', '10783', '12559', '14050', '10969', '10367', '12207', '13409', '10555', '10623', '10249', '10315', '12109', '12055', '13353', '13509', '10407', '12051', '12159', '10629', '13503', '13591', '10961', '10777', '13439', '13057', '10999', '12309', '12437', '10781', '12305', '10965', '12167', '10318', '10409', '12359', '10779', '14169', '10437', '12161', '10589', '13581', '12679', '13505', '12555', '10405', '10119', '13355', '10179', '12357', '13469', '13351', '14055', '14089', '10627', '10829', '12107', '12435', '10319', '13507', '10551', '13437', '13347', '13627', '12524', '13599', '13189', '13129', '13467', '12589', '12489', '10825', '13585', '10625', '12527', '13405', '10439', '13597', '10317', '10553', '12101', '10557', '12355', '13587', '13053', '10967', '12439', '13589', '10707', '13629', '13088', '10719', '10243', '12045', '12105', '12349', '13125', '10117', '14199', '13187', '13357', '13349', '13403', '10178', '12047', '13055', '12165', '12249', '13407', '12169', '12587', '14053', '14052', '12103', '10245', '14193', '12205', '10827', '10585', '10587', '12557', '10435', '12623', '10713', '12059', '13059', '14109', '13051', '13127', '12307', '10715', '14057', '14195', '12619', '13158', '12043', '13089', '10711', '10997', '12099', '10247', '10709', '13595', '14165', '12247', '13159', '14167', '10789', '12049', '14197', '10559', '10115', '14163'}
Hamburg {'22589', '22305', '22587', '22395', '20457', '22391', '22763', '20359', '22393', '22527', '20249', '22605', '21037', '27499', '22547', '20097', '22147', '20255', '22765', '22115', '22309', '20259', '22767', '20095', '22399', '22113', '22087', '21129', '22299', '22159', '22083', '22455', '20144', '21033', '22119', '20354', '22145', '22041', '22049', '21035', '21077', '20099', '20459', '20149', '21031', '22453', '20539', '21039', '22297', '22149', '20251', '22607', '22529', '22179', '21075', '22339', '22397', '22335', '22047', '22175', '22085', '21079', '22303', '22111', '22525', '21107', '20537', '22143', '21029', '22081', '20253', '22301', '22337', '21109', '22459', '20355', '22559', '22549', '22761', '21149', '20357', '22415', '22307', '22177', '22045', '20146', '22457', '22089', '22417', '22769', '22419', '22117', '22609', '20535', '21073', '20257', '22523', '22359', '20148', '22043', '21147'}
München {'81241', '81669', '80336', '80796', '80799', '80339', '80539', '80689', '80939', '81929', '80634', '81249', '81545', '80469', '81475', '80803', '81371', '81373', '81476', '80686', '80999', '81667', '81927', '80804', '81739', '80997', '80687', '80798', '80933', '81477', '81541', '81369', '81379', '81549', '81675', '80637', '80801', '80992', '80993', '81377', '81543', '81677', '81925', '81479', '81247', '80337', '81673', '85540', '80802', '80797', '80333', '80638', '81827', '81671', '80809', '80639', '81547', '81825', '81245', '81829', '81243', '81375', '81737', '80805', '80335', '81679', '80331', '80636', '80935', '80538', '80807', '80937', '81539', '80995', '81735'}
Köln {'50939', '50827', '50668', '50676', '50999', '51065', '50968', '50733', '50937', '50769', '51147', '50670', '51061', '50823', '50767', '50829', '50674', '51069', '50735', '50672', '50679', '50737', '50931', '50678', '50969', '51103', '50667', '50858', '50859', '50933', '51105', '51467', '51063', '51107', '50825', '50996', '51109', '51145', '50935', '50765', '51067', '50997', '51149', '50739', '50677', '51143'}
Frankfurt am Main {'60437', '60311', '60439', '60329', '60549', '60320', '60322', '60486', '65934', '60489', '60599', '60438', '60431', '60594', '60529', '60488', '60386', '60310', '60306', '60325', '60313', '60598', '65931', '60389', '60308', '65936', '60327', '60435', '60385', '60316', '60596', '60433', '60318', '60528', '65933', '60487', '60314', '60388', '60323', '65929', '60326'}
Essen {'45259', '45276', '45327', '45145', '45138', '45355', '45219', '45257', '45326', '45141', '45128', '45277', '45130', '45289', '45279', '45139', '45307', '45356', '45136', '45144', '45239', '45357', '45147', '45131', '45359', '45127', '45329', '45309', '45134', '45143', '45133', '45149'}
Dortmund {'44139', '44263', '44141', '44267', '44265', '44319', '44145', '44289', '44339', '44229', '44309', '44357', '44147', '44379', '44143', '44149', '44227', '44328', '44135', '44359', '44137', '44329', '44269', '44287', '44369', '44388', '44225'}
Stuttgart {'70191', '70186', '70193', '70195', '70176', '70378', '70197', '70327', '70435', '70192', '70376', '70182', '70174', '70569', '70190', '70188', '70597', '70374', '70567', '70499', '70599', '70184', '70329', '70178', '70565', '70563', '70439', '70629', '70469', '70619', '70199', '70372', '70173', '70180', '70437'}
Düsseldorf {'40227', '40215', '40549', '40225', '40593', '40476', '40625', '40231', '40595', '40221', '40217', '40229', '40470', '40721', '40489', '40627', '40479', '40212', '40211', '40219', '40235', '40547', '40223', '40477', '40629', '40233', '40599', '40589', '40597', '40213', '40237', '40472', '40474', '40468', '40591', '40210', '40545', '40239'}
Bremen {'28195', '28201', '28215', '27568', '28759', '28307', '28755', '28217', '28279', '28777', '28213', '28719', '28325', '28197', '28779', '28757', '28209', '28309', '28207', '28219', '28277', '28203', '28199', '28327', '28237', '28205', '28211', '28329', '28717', '28357', '28359', '28355', '28239', '28259'}
Hannover {'30459', '30519', '30627', '30669', '30539', '30419', '30177', '30521', '30629', '30559', '30453', '30655', '30659', '30169', '30455', '30449', '30179', '30175', '30625', '30159', '30451', '30171', '30457', '30657', '30165', '30173', '30161', '30163', '30167'}
Duisburg {'47249', '47229', '47055', '47179', '47138', '47139', '47198', '47057', '47166', '47199', '47279', '47169', '47259', '47269', '47228', '47137', '47226', '47119', '47051', '47167', '47058', '47059', '47239', '47178', '47053'}
Leipzig {'4155', '4289', '4357', '4205', '4349', '4229', '4288', '4275', '4209', '4179', '4347', '4328', '4177', '4129', '4319', '4178', '4318', '4277', '4315', '4103', '4105', '4317', '4249', '4316', '4158', '4329', '4109', '4356', '4279', '4107', '4207', '4159', '4157', '4299'}
Nürnberg {'90480', '90482', '90427', '90475', '90411', '90471', '90439', '90403', '90478', '90451', '90443', '90431', '90453', '90473', '90459', '90469', '90402', '90408', '90455', '90489', '90441', '90449', '90461', '90419', '90491', '90425', '90409', '90429'}
Dresden {'1159', '1139', '1326', '1187', '1156', '1069', '1108', '1099', '1465', '1109', '1127', '1169', '1324', '1328', '1259', '1277', '1239', '1257', '1237', '1217', '1157', '1097', '1219', '1307', '1309', '1129', '1189', '1279', '1067'}
Bochum {'44869', '44809', '44799', '44787', '44803', '44867', '44801', '44866', '44795', '44894', '44793', '44805', '44807', '44791', '44879', '44797', '44892', '44789'}
Wuppertal {'42389', '42399', '42327', '42115', '42107', '42279', '42109', '42103', '42369', '42111', '42275', '42117', '42113', '42283', '42281', '42329', '42105', '42289', '42119', '42277', '42287', '42349', '42285'}
Bielefeld {'33613', '33699', '33729', '33611', '33602', '33615', '33739', '33605', '33659', '33609', '33689', '33617', '33647', '33619', '33719', '33607', '33604', '33649'}
Mannheim {'68199', '68309', '68239', '68305', '68161', '68167', '68165', '68229', '68159', '68307', '68163', '68259', '68169', '68219'}
Another Comprehensive Example
We want to present another real life example in our Python course. A regular expression for UK postcodes.We write an expression, which is capable of recognizing the postal codes or postcodes of the UK.
Postcode units consist of between five and seven characters, which are separated into two parts by a space. The two to four characters before the space represent the so-called outward code or out code intended to directly mail from the sorting office to the delivery office. The part following the space, which consists of a digit followed by two uppercase characters, comprises the so-called inward code, which is needed to sort mail at the final delivery office. The last two uppercase characters do not use the letters CIKMOV, so as not to resemble digits or each other when hand-written.
The outward code can have the following form: One or two uppercase characters, followed by either a digit or the letter R, optionally followed by an uppercase character or a digit. (We do not consider all the detailed rules for postcodes, i.e only certain character sets are valid depending on the position and the context.)A regular expression for matching this superset of UK postcodes looks like this:
r"\b[A-Z]{1,2}[0-9R][0-9A-Z]? [0-9][ABD-HJLNP-UW-Z]{2}\b"
The following Python program uses the regexp above:
import re
example_codes = ["SW1A 0AA", # House of Commons
"SW1A 1AA", # Buckingham Palace
"SW1A 2AA", # Downing Street
"BX3 2BB", # Barclays Bank
"DH98 1BT", # British Telecom
"N1 9GU", # Guardian Newspaper
"E98 1TT", # The Times
"TIM E22", # a fake postcode
"A B1 A22", # not a valid postcode
"EC2N 2DB", # Deutsche Bank
"SE9 2UG", # University of Greenwhich
"N1 0UY", # Islington, London
"EC1V 8DS", # Clerkenwell, London
"WC1X 9DT", # WC1X 9DT
"B42 1LG", # Birmingham
"B28 9AD", # Birmingham
"W12 7RJ", # London, BBC News Centre
"BBC 007" # a fake postcode
]
pc_re = r"[A-z]{1,2}[0-9R][0-9A-Z]? [0-9][ABD-HJLNP-UW-Z]{2}"
for postcode in example_codes:
r = re.search(pc_re, postcode)
if r:
print(postcode + " matched!")
else:
print(postcode + " is not a valid postcode!")
OUTPUT:
SW1A 0AA matched! SW1A 1AA matched! SW1A 2AA matched! BX3 2BB matched! DH98 1BT matched! N1 9GU matched! E98 1TT matched! TIM E22 is not a valid postcode! A B1 A22 is not a valid postcode! EC2N 2DB matched! SE9 2UG matched! N1 0UY matched! EC1V 8DS matched! WC1X 9DT matched! B42 1LG matched! B28 9AD matched! W12 7RJ matched! BBC 007 is not a valid postcode!
Live Python training
Enjoying this page? We offer live Python training courses covering the content of this site.
Upcoming online Courses
28 Jul to 01 Aug 2025
08 Sep to 12 Sep 2025
20 Oct to 24 Oct 2025
01 Dec to 05 Dec 2025
Efficient Data Analysis with Pandas
28 Jul to 29 Jul 2025
08 Sep to 09 Sep 2025
20 Oct to 21 Oct 2025
01 Dec to 02 Dec 2025
Python and Machine Learning Course
28 Jul to 01 Aug 2025
08 Sep to 12 Sep 2025
20 Oct to 24 Oct 2025
01 Dec to 05 Dec 2025
See our Python training courses